

What are ML Pipelines? Analysis and Conclusion
This is the 2nd part in a series of two blog articles called “Data Pipelines Vs. ML Pipelines – Similarities, and Differences”. If you haven’t read the 1st part yet, we recommend you do so first.
What are ML Pipelines
Let’s now look at the ML Pipeline. Like the Data Pipeline, it’s a process linking several specific modules. The goal of the ML Pipeline is to enable organizations to learn from their data and make advanced predictions. ML Pipelines are generally used and built by Data Scientists. Building, testing, optimizing, training, inferencing, and maintaining the accuracy of the ML models are complex and challenging. Successful ML projects need a well-structured ML Pipeline to run smoothly and efficiently.
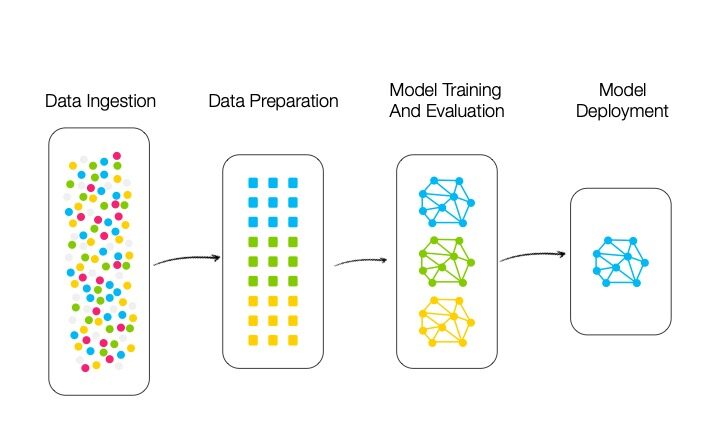
ML Pipelines
As can be seen in the figure above, the architecture of an ML Pipeline contains four main modules: Data Ingestion, Data Preparation, Model Training and Evaluation, and Model Deployment. We describe each module in detail below.
1. What is Data Ingestion in the ML Pipelines
The first step of ML Pipelines is to gather and funnel the real-life data needed to make accurate predictions and recommendations. The data is usually captured at the edge of the network through ingestion points, such as in-store point-of-sale devices, cars, security monitoring, or medical devices.
This data can be obtained either on a trigger or streamed regularly on a schedule. The amount of data collected by these smart edge devices can be huge. However, it is generally preferred to keep the data persisted without undertaking any transformation to allow an undisputable record of the original data. Depending on the business case, the smart edge devices can push or be programmed to stream smaller data sets multiple times a day or several times per hour, to reduce bandwidth requirements and accelerate data movement. To further improve performance, the ingestion should use dedicated pipelines for each ingestion point to be processed independently and in parallel.
The raw data collected by the ingestion points are transferred to a central raw historical Data Lake generally located in the cloud to ensure scalability. This data can also be stored locally (think Uber and Lyft arrival time prediction, for example). For large implementations and to reduce the overall time to complete the ingestion, the historical Data Lake can be partitioned across several data servers, multiple server cores, and processors. As with the Data Pipeline, enterprises can opt to keep the raw historical operational data on the operational systems (ERP, CRM) themselves.
Data scientists do not have the time nor the technical knowledge to build such a sophisticated ingestion process. It is recommended that they use a reliable, easy-to-use, point-and-click ML platform to help them set up a process that fits their business requirements, painlessly.
2. What is Data Preparation in the ML Pipeline
The second step in the ML Pipeline is to prepare the raw data for training. This module is generally referred to as data scrubbing and preparation, data pre-processing, or data augmentation. It is equivalent to the ELT layer described in the Data Pipeline section but with additional twists and turns.
During Data Preparation, data anomalies are found and rectified. These include format differences, incorrect inputs, or missing fields. The data can be augmented and correlated with additional information from other enterprise or external data sources to make the data more complete for smarter predictions.
Feature selection also happens at this stage. The features are specific properties of the observed data, used for pattern recognition, regression, and classification. The selected features are stored in a separate low-latency feature data store.
At the beginning of an ML project, the prepared data is segregated into two subsets: One to train the model, the other to validate it. A default or custom ratio is allocated (at least three fourth of the data) for training and the remainder for testing and validation. Further along in the ML project, as new data is gathered, it is segregated again using similar ratios, for periodic re-training, performance improvement, and validation.
This step is one of the most complex parts of the ML Pipeline. Doing it right is crucial to the success of the project. Using an intuitive ML management system to effortlessly gather different data types together, fix the anomalies, and create the segmentation is key to a speedy and effective ML project.
3. What are Model Training and Evaluation in the ML Pipelines
Module three focuses on training the predictive models. The prepared data from the previous step is streamed to a training datastore on which the training algorithms are run.
Traditional highly structured RDBMSs are still popular for storing training and learning models because of their familiar data architecture, and the well-known SQL (Structured Query Language) used to manage the data sets. However, as ML data sets continuously grow, enterprises move towards unstructured database systems like NoSQL. These database systems trade-off rigorous RDBMS data structure requirements for agility and speed. They welcome different file formats and are designed for high-performance and nimble processing at massive scale. A software management system like Hadoop, specialized in massively parallel computing is added, to manage distributed databases stored across multiple processing nodes and servers.
Several models can be trained and evaluated together. This step will help determine when the models are ready for deployment and which ones are best to deploy. The predictive models are evaluated by comparing their predictions with known true values. A variety of accuracy metrics and evaluators are used, and saved with the models in the training data store. A well-designed AI management system should have enough flexibility to accommodate several models, and to allow combining and switching between various evaluators. The models are fine-tuned and trained again running samples through them until a specified level of accuracy is reached, called convergence. This is an iterative process. Each new instance of the model and its the evaluation results are saved for future reference in the repository. Data from past iterations may be saved indefinitely.
This repetitive training phase is very compute-intensive and read-write-heavy. It usually runs off-line and is not real-time. It can take quite a while before a model reaches convergence. Data scientists need a system to help them easily set up the proper evaluation metrics and architect a training data store that delivers high bandwidth and scalability. They also need to adopt an ML management system that can support structured RDBMS and massively scalable unstructured database systems depending on their business needs.
4. What is Model Deployment in the ML Pipeline
At this stage, the trained models that have reached an acceptable level of accuracy are moved to a production environment. Once the chosen model is in production and real-world data is collected from the ingestion points, the ML data sets will grow aggressively and continuously. Note that more than one model can be deployed at any time to enable safe transition between the different model iterations.
Most prediction models today run off-line and in batch-mode, using daily inventory numbers, for example, for tomorrow morning’s order reports. They are commonly used to add insight to existing operational reports and executive dashboards. Although fewer companies effectively run real-time prediction models today, the trend is going in that direction. Other more early adopter-type enterprises have set up both real-time and batch-mode prediction models for different types of data – sales forecasts and consumer behavior predictions, for example.
A flexible architecture needs to be put in place to accommodate these different types of models and their extremely high growth. The ML models will continuously go through the data to make predictions. Therefore, it is essential to deploy a storage system that supports large amounts of data and has extremely low latency. The prediction models should be deployed in container service clusters, distributed for load balancing to assure scalability, low latency, and high throughput, like Docker and Kubernetes.
Data scientists should be able to easily manage the complex process of setting up such an advanced ML architecture through an advanced ML management system. This system should be enterprise-grade, scalable, secure, offer advanced version control, and allow loading ML models in any cloud-based execution environment.
What is Performance Monitoring in the ML Pipelines
Once in production, a model is continuously monitored to observe how it behaves in the real world. A model scoring system and process must be implemented to evaluate the model in production. A comprehensive model scoring system must consider other performance factors than accurate predictions and recommendations and include performance metrics such as latency, efficiency, and throughput.
Depending on the business case, these performance metrics can determine performance for high-batch/ high-throughput “after-hours” workloads where predictions are created on a periodic schedule or for real-time latency-sensitive performance where predictions are produced on-demand and return the correct answers immediately.
Once deployed, models are continuously monitored using real-world data, which often contains changed consumer behaviors and trends, new product introductions, market competitive changes, and economic and environmental shifts. If the model does not meet these production metrics during real-world production, the model needs to be recalibrated. The model is sent back to the Training and Evaluation stage, and a new version is created based on the changes.
Model monitoring is a continuous process. Data scientists need a system to help them quickly find a shift in prediction that might require restructuring the model. An ML management system that automatically and thoroughly logs all model changes is important to the success of an ML model setup and deployment.
Once in production, a model is continuously monitored to observe how it behaves in the real world. A model scoring system and process must be implemented to evaluate the model in production. A comprehensive model scoring system must consider other performance factors than accurate predictions and recommendations and include performance metrics such as latency, efficiency, and throughput.
Depending on the business case, these performance metrics can determine performance for high-batch/ high-throughput “after-hours” workloads where predictions are created on a periodic schedule or for real-time latency-sensitive performance where predictions are made on-demand and return the correct answers immediately.
Once deployed, models are continuously monitored using real-world data, which often contains changed consumer behaviors and trends, new product introductions, market competitive changes, and economic and environmental shifts. If the model does not meet these production metrics during real-world production, the model needs to be recalibrated. The model is sent back to the Training and Evaluation stage, and a new version is created based on the changes.
Model monitoring is a continuous process. Data scientists need a system to help them quickly find a shift in prediction that might require restructuring the model. An ML management system that automatically and thoroughly logs all model changes is important to the success of an ML model setup and deployment.
Analysis and Conclusion
Data Pipelines can be complex and challenging to build. Fortunately, Data Pipelines have been around for a while, and today we can find many well-honed tools to help us make them. The complexity and challenges increase ten-fold when building and maintaining an ML Pipeline. This is mainly due to the increasing real-time aspect of an ML Pipeline and the vast amounts of data required for a model to reach acceptability, the data sets’ massive growth characteristics, and the continuous learning aspects of the ML model.
The ML Pipeline needs to support testing different models and storing all the different versions of each model before deploying the best one. ML models need to continuously be monitored for performance and prediction accuracy and updated to reflect user and market changes.
We’ve also seen that both pipelines ingest data from the same operational data sources, transform it, and store it in a central data store. So the natural question to ask is: Can an ML Pipeline be incorporated into an already existing Data Pipeline? The answer is yes. And it actually makes a lot of sense, as the data comes from the same data sources and can be sent to the same destinations.

Example of a ML Pipeline and a Data Pipelines Together
The image above depicts one possible way an ML Pipeline can be joined to an existing Data Pipeline. As ML Data Scientists are hired to set up an ML project, they’ll naturally ask if they can access already existing clean data sets. To correctly graft their ML Pipeline onto the existing Data Pipeline, they’ll need to establish if the existing data fit their needs to run their ML models or if additional data sources need to be tapped into. From a security perspective, they’ll need to determine their access rights. Since predictive models have a relentless appetite for data, they’ll need to define how much additional disk space they’ll need to run their ML models.
Data Pipelines are generally built by Data Engineers and used by Business Users, whereas ML Pipelines are typically used and built by Data Scientists. Joining the ML Pipeline and the Data Pipeline together creates a collaborative platform that allows Data Engineers and Data Scientists to work together and business users to equally benefit from the predictive models. The newly found predictions and recommendations can be stored back to the Data Warehouse and added to the data sets to complement the information presented by the Reporting and Analytics tools for greater business insight.
ML Pipelines are relatively new compared to Data Pipelines. Data Scientists need an ML Pipeline management system that can easily manage the whole ML process end-to-end. This includes setting up the ingestion process, the data transformation paradigm, and the model testing and learning modules. This ML management system should automatically and thoroughly log all model changes and offer advanced model version control features. The ML Pipeline management system should be an end-to-end management platform that allows Data Scientists to easily graft an ML Pipeline branch to an existing Data Pipeline. It should also be enterprise-grade, scalable, secure, and work in any cloud-based execution environment.
Thank you for reading the second part of this two-part blog. If you haven’t done so, you can read the 1st part here.
For more articles on data, analytics, machine learning, and data science, follow me on Towards Data Science.
Get started with ForePaaS for FREE!

Discover how to make your journey towards successful ML/ Analytics – Painless


